- Posted April 9, 2013, 9:01 a.m. - 11 years ago
What is OCR?
OCR stands for optical character recognition. It’s a process that allows text on a piece of paper to be converted into text that can be edited on a computer, without the need for the page to be manually re-typed.
Getting printed text to editable text involved a few separate steps.
- The printed page is scanned into the computer using an ordinary scanner. This results in a large image file – just like a scanned photograph.
- Using OCR software, the text on the page is analysed. The software effectively interprets the patterns of light and dark on the page and attempts to convert those patterns into their text equivalents. There are various tools that you can use to achieve this; Google Drive has a very basic OCR conversion tool, for example, and it’s free to use. Alternatively, your scanner software may offer something more convenient.
- Finally, you need to save the output from the OCR software. When saving as a PDF, you can save both types of data in the same file. Otherwise, you might be prompted to save the scan data as an image and the OCR data as separate a text file.
Scanning a printed page and converting with OCR to PDF format is a handy way to make your PDF content more usable. Rather than saving as a flat image file, saving a scan as a PDF with OCR data gives you the chance to index, search and edit the content of that scan.
Note: From version 6 onwards, Infix will be able to import the scanned image and process it to create OCR data. This saves you the inconvenience of finding a third-party tool to do the same job.
The Quirks of OCR
OCR is a fantastically useful technique, but it isn’t completely fool proof. Scanning a page and turning it into editable characters isn’t an exact science, and there are almost always errors in the converted text.
That’s because OCR involves converting analogue data (i.e. a scanned image) to digital data, and analogue data normally contains marks and ‘noise’ that result in inaccuracies in the digital version.
Hidden OCR data in a PDF is important – one of its most important uses is powering the search functionality within the document. Publishers therefore need to ensure that their OCR data accurately reflects the contents of the scanned text.
So how do you go about viewing it?
Infix OCR Corrections Tool
Infix has a feature called the OCR Corrections Tool. This allows you extract, analyse and correct the hidden OCR data in a PDF file so that your end user can benefit from accurate searching.
Remember: in order to use this tool, you’ll need to have scanned your document and processed it with OCR software first. The OCR Corrections Tool can only be used once those first two steps have been completed.
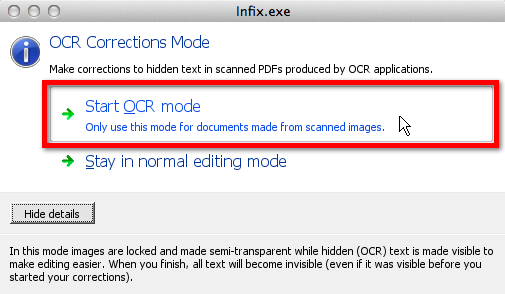
To use OCR Corrections, go to Documents -> OCR Corrections -> Start. You will be prompted to Start OCR mode (highlighted in red below); this view shows actual text and any non-printing characters that affect its layout.

In this mode, you can read through the text captured by your OCR tool and correct it as necessary.
When you are done correcting the OCR data in your PDF, go to Documents -> OCR Corrections -> Finish. Remember to save your PDF file to ensure your edited OCR text is saved.
Latest Articles
-
Our latest testimonial for Infix 6
Dec. 19, 2016, 2:40 p.m. -
Most commonly translated Turkish words
Feb. 6, 2015, 9 a.m. -
Merry Christmas & A Happy New Year
Dec. 25, 2016, 8 a.m. -
New Save PDF to SVG feature introduced to Spire.Office
Dec. 23, 2016, 11:54 a.m. -
Editing educational PDFs – a user perspective
July 21, 2014, 8:03 a.m.
Categories
Iceni Technology Ltd.,
36 St. Faiths Lane,
Norwich, England, NR1 1NN